Python Celery Task Queue For My Browser Game
Outside the HTTP request cycle, I need something that handles asynchronous tasks, like periodically running NPC actions. Enter Celery.


Outside the HTTP request cycle, I need something that handles asynchronous tasks, like periodically running NPC actions. Enter Celery, the distributed task queue software.
Historically, there are tools like cron for scheduling repetitive tasks. Celery provides far, far more than that, though. Like task groups, tasks spawning tasks, and more.
One of the value propositions for Celery I've heard is also a scathing criticism: Celery exposes countless options for tuning, and flexibility to run all sorts of workloads and tasks. Thus, Celery is a hugely complex distributed system.
You'll find few words strung together that are more frightening to operations-oriented tech workers. Complex, distributed systems are prone to "interesting" issues. They're the cause of sleepless nights and hours of troubleshooting.
However, I've been finding it worthwhile to learn Celery. I've used it in a simpler project before, and it was overkill for that project. However, the lessons learned from that project made it smoother to adopt Celery for Blasphemess.
Another benefit of adopting Celery over rolling my own system is that there's a pre-existing ecosystem of tools for monitoring and telemetry. For instance, I use Jaeger, Open Telemetry, and Flower in my observability stack.
Let's dive into what Celery brings to my use case!
The Synchronous HTTP Request Cycle and Asynchronous Tasks With Celery
Within my game, there are two ways things happen: synchronously when a player acts (i.e. they push a button to do something), and asynchronously when the tasks queue infrastructure picks up a task job to complete.
What these timings relate to is the HTTP Request-Response Cycle: when a player clicks a button, it will send a request such as POST /actions/random_respawn. The game's backend runs some game code, then when it finishes it responds with an HTTP Response, e.g. HTTP 200 OK.
That means that once the client receives the HTTP Response, all the execution is done. The client is waiting that whole time, as would be the case when loading a page. This is synchronous.
However, for some requests, the game code might spawn an asynchronous task before it responds with the HTTP Response. As an example:
A player clicks the attack button. It launches the game logic for combat, which does synchronous operations (like changing the health points of a character) and then creates asynchronous tasks. Then it returns, and sends back the HTTP Response.
However, those asynchronous tasks are still in the queue at this point. At any point from milliseconds to minutes later, the Celery cluster will pick up the tasks and process them.
In this case, after the combat is run, the asynchronous task might be the on_entity_death logic, which handles things like sending messages about the total lifespan of the character, or demoting NPC levels for those that died too often.
The key point is that whilst the task may be started by a player action, it is processed independently, asynchronously, at an uncertain point in the future – or it could fail entirely, if there's trouble.
There's another way asynchronous tasks are created, however:
Periodic Tasks and Celery Primitives
Celery also has a component called beat. Celery beat allows scheduling periodic tasks, stuff that is repeated every given time. For Blasphemess, an example of this is running auto-actions every 6 seconds. Or the task to regenerate action points every few minutes.
Auto-actions are not so simple, though: they take advantage of the fact that tasks in Celery can spawn their own tasks.
Celery provides several composable primitives that can be used to build a complex pipeline of tasks, including chains and groups.
Luckily, my game does not need full coverage of those features; I'm content with spawning tasks within tasks. This allows me to create an "entry point" such as auto_action_entrypoint. This creates tasks for each location in the game, distributing the load and building fault compartmentalisation into the game.
Here's what the code looks like:
@celery_app.task(acks_late=False, max_retries=0, expires=12.0)
def auto_action_entrypoint():
try:
db: Session = SessionLocal()
group_list = []
for plane in crud.plane.get_all_planes(db=db):
if "void" in plane.tags:
continue
for district in crud.district.get_by_plane(db=db, plane_name=plane.name):
# Add a task for running combat in the outside of the district
group_list.append(
auto_action_location.s(
plane_name=plane.name,
district_name=district.name,
inside=False,
x=None,
y=None,
)
)
# Add a task for running combat in all the tiles inside the district
for tile in crud.tile.get_by_district(
db=db, plane_name=plane.name, district_name=district.name
):
if tile.enterable:
group_list.append(
auto_action_location.s(
plane_name=plane.name,
district_name=district.name,
inside=True,
x=tile.x,
y=tile.y,
)
)
if not group_list:
return
job = celery.group(group_list)
job.apply_async()
except Exception:
db.rollback()
raise
finally:
db.close()
@celery_app.task(acks_late=False, max_retries=0, expires=60.0)
def auto_action_location(
plane_name: str,
district_name: str,
inside: bool,
x: int | None,
y: int | None,
):
try:
db: Session = SessionLocal()
auto_action.run_auto_action_location(
db=db,
plane_name=plane_name,
district_name=district_name,
inside=inside,
x=x,
y=y,
)
except Exception:
db.rollback()
raise
finally:
db.close()Code for the auto action entry point and per-location tasks.
This means that only one Celery signature needs to be registered as a periodic task, but it spawns tasks for each of the (game-server-specific) locations:
@celery_app.on_after_finalize.connect
def setup_periodic_tasks(sender: celery.Celery, **kwargs):
del kwargs
# [...]
sender.add_periodic_task(6.0, auto_action_entrypoint.s()) # Every six seconds
Code for setting up the periodic task with Celery beat to run auto-actions every six seconds.
Celery Observability and Operations
Using Celery comes with quality of life tools, based around observability and monitoring. For instance, there's Flower. It provides detailed, real-time information about tasks, workers, and the message broker.

This is great when developing, debugging, or even tracing problems in production.
For instance, I recently did a simple performance test by spawning thousands of NPCs. Sure enough, things broke down! However, I needed to be able to pinpoint exactly what had broken, so that I could fix it. Flower helped me identify that the tasks were running too long, and timing out.
There is another tool in my observability stack, though: Jaeger, using Open Telemetry (OTel).
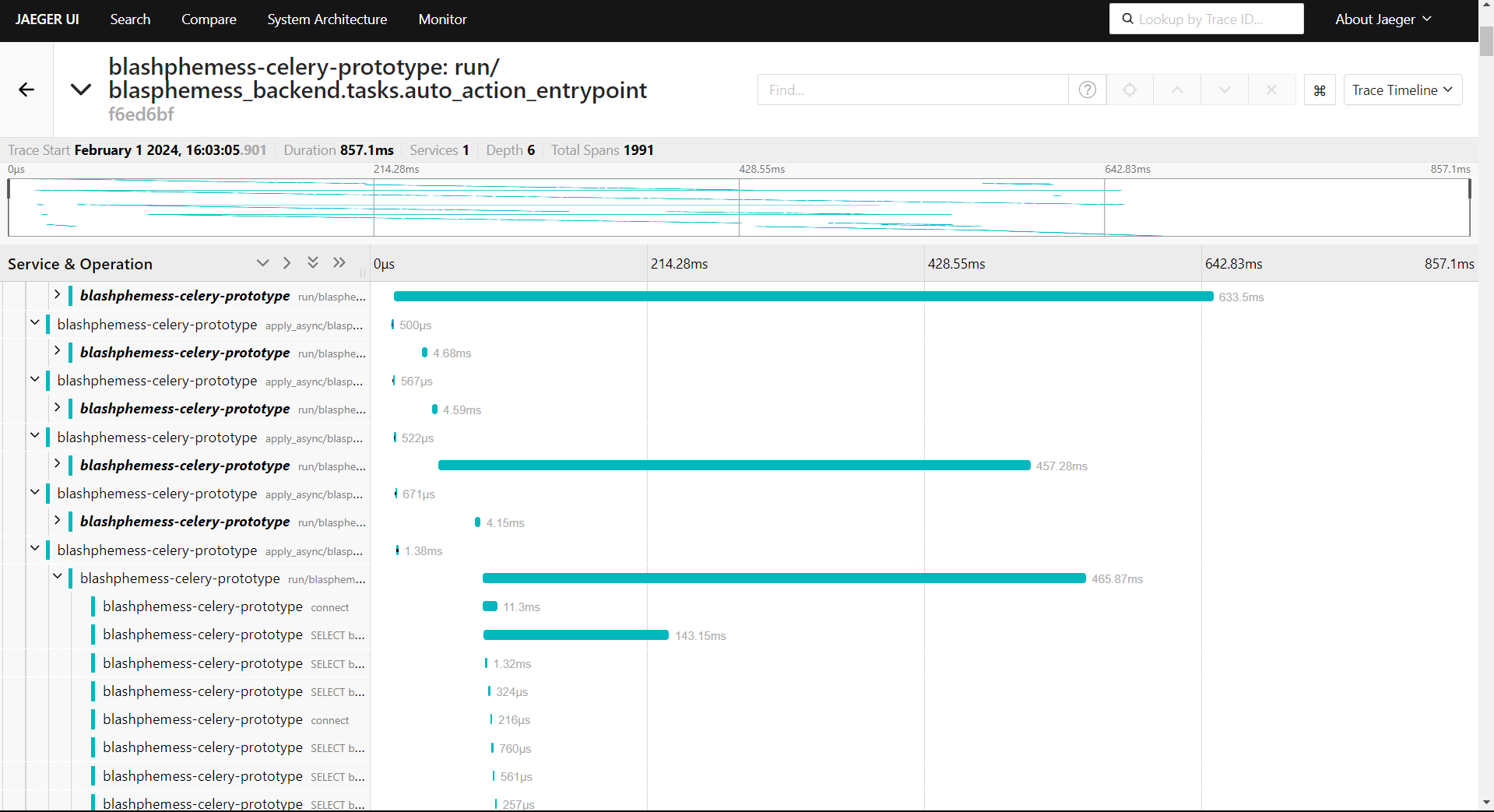
Jaeger gives me insight into the trace timeline of both Celery tasks and HTTP requests that my FastAPI backend receives. It also connects up to my database to show what operations are going on!
This means that I can see deep into my code, to find slow bits of code execution, as well as how quickly overall tasks/requests run.
In the below picture, the auto-action entry point span takes a total of 850 milliseconds to complete – nearly a full second. In the trace timeline, you can see that there are several parallel tracks of traces, where different Celery workers are processing at the same time. Beneath that, there's the individual span details, which can be collapsed or expanded to show details such as single SQL statements.
In Conclusion
Celery has been fun to learn, and I look forward to seeing how well it holds up in production once I release the pre-alpha prototype of Blasphemess.
Thus far in development, it has been easy to handle. However, I'm still using but a single node "cluster" of Celery. Adding in networking, multiple nodes, and more complexity is a recipe for trouble.
Still, these problems are conquerable with effort.
Those problems are also well worth the benefit, as my game has the ability to run lots of tasks outside player-initiated code.



